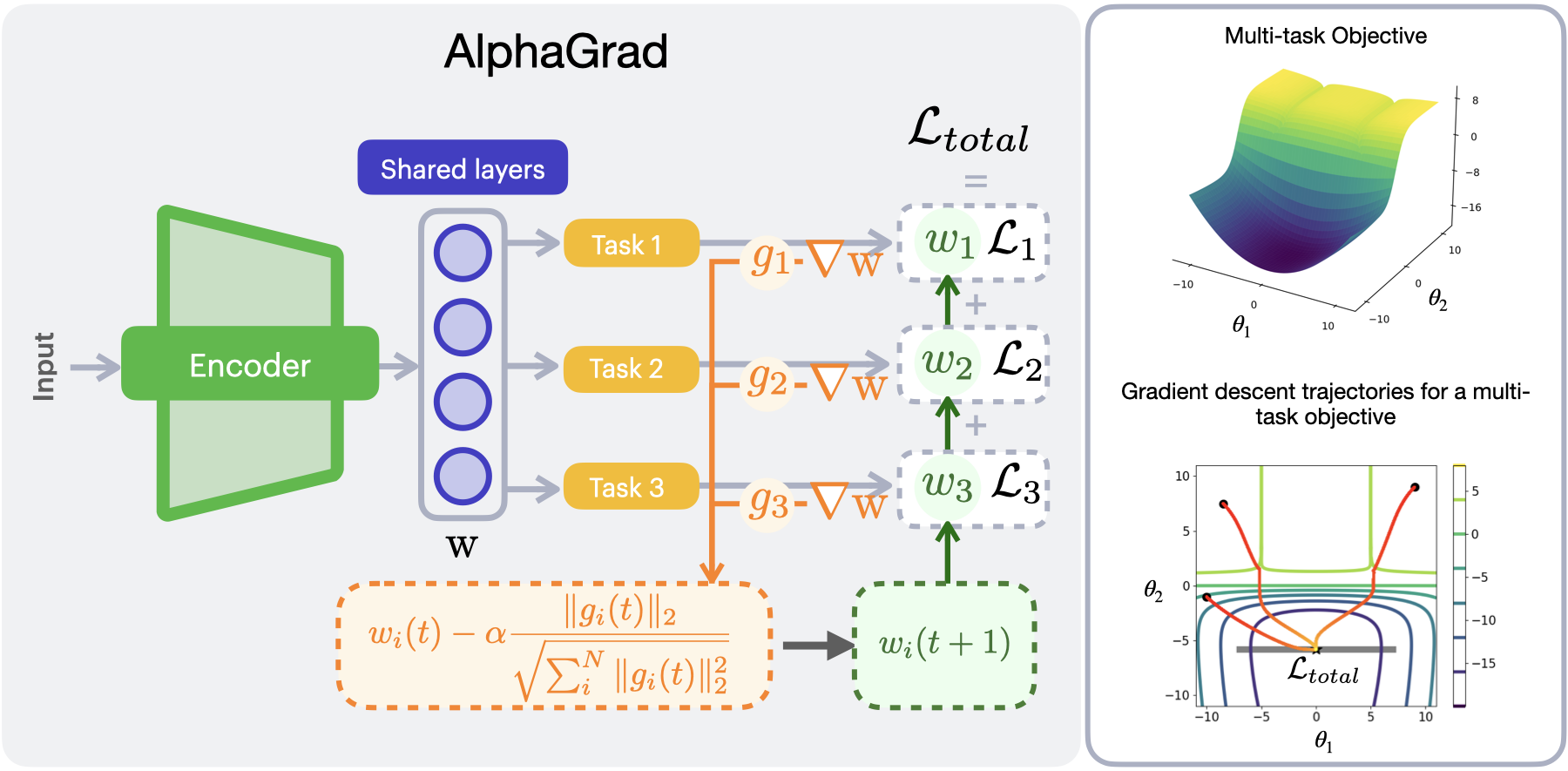
In this study, we propose AlphaGrad, a novel adaptive loss blending strategy for optimizing multi-task learning (MTL) models in motor imagery (MI)-based
electroencephalography (EEG) classification. AlphaGrad is the first method to automatically adjust multi-loss functions with differing metric scales,
including mean square error, cross-entropy, and deep metric learning, within the context of MI-EEG. We evaluate AlphaGrad using two state-of-the-art MTL-based
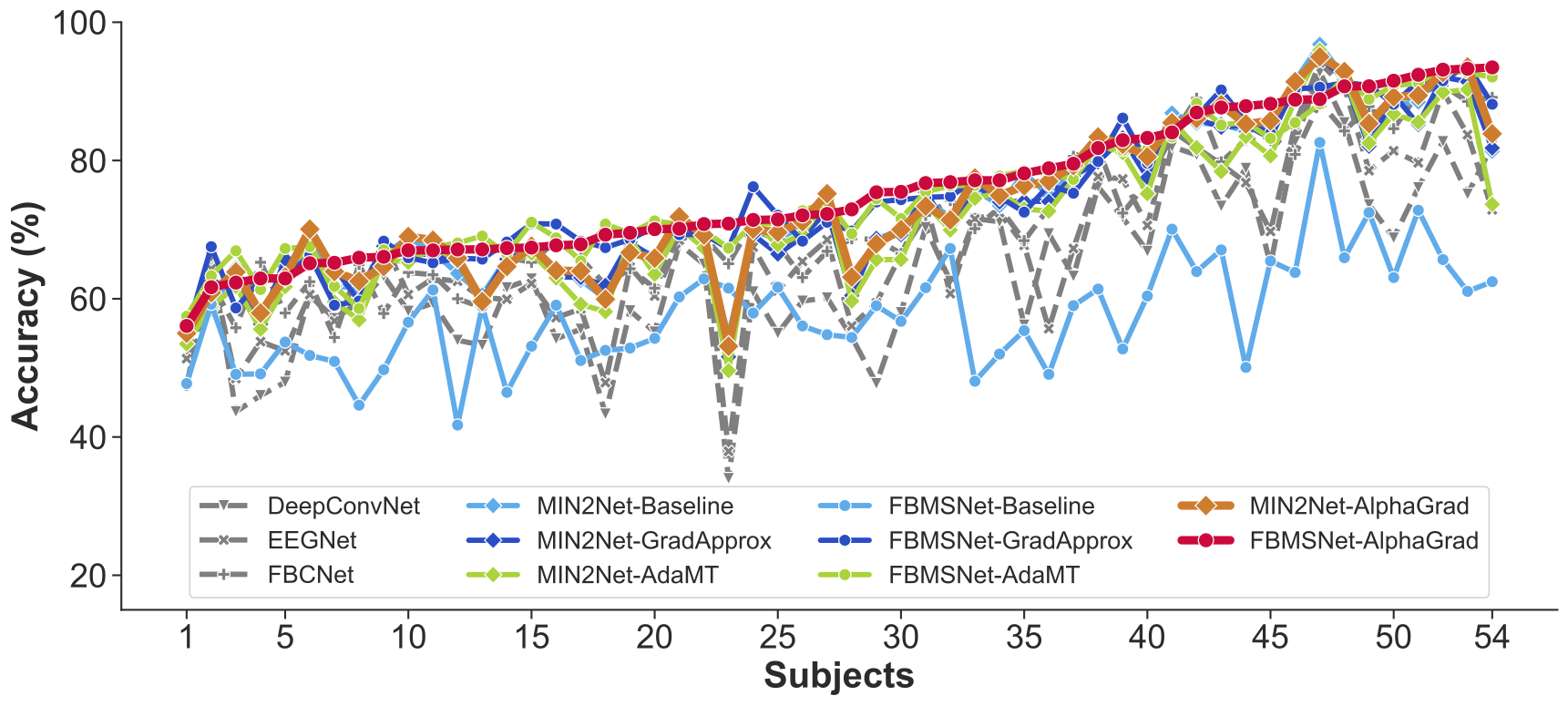
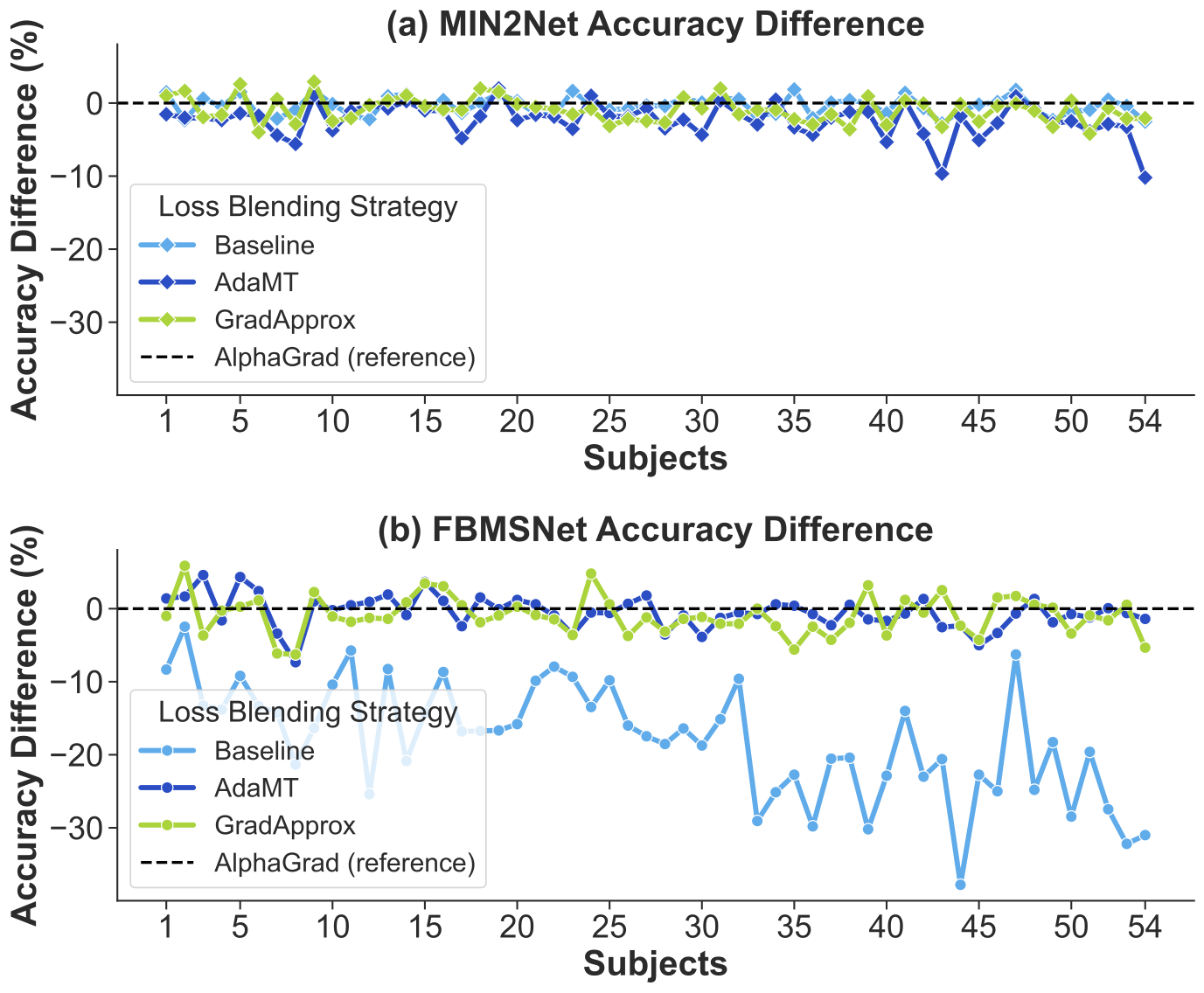
neural networks, MIN2Net and FBMSNet, across four benchmark datasets. Experimental results show that AlphaGrad consistently outperforms existing strategies
such as AdaMT, GradApprox, and fixed-weight baselines in classification accuracy and training stability. Compared to baseline static weighting,
AlphaGrad achieves over 10% accuracy improvement on subject-independent MI tasks when evaluated on the largest benchmark dataset. Furthermore,
AlphaGrad demonstrates robust adaptability across various EEG paradigms—including steady-state visually evoked potential (SSVEP) and event-related potential (ERP),
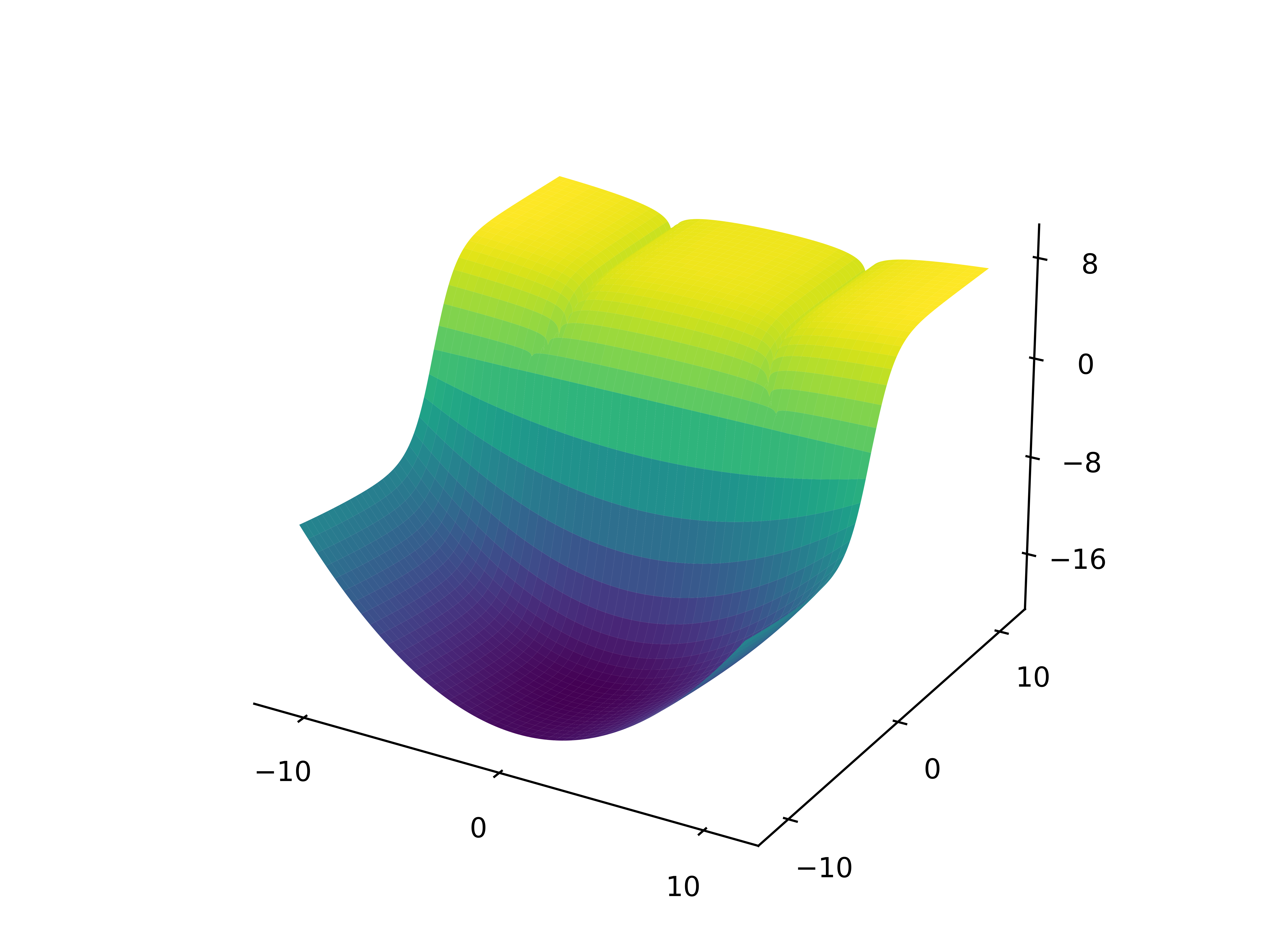
making it broadly applicable to brain-computer interface (BCI) systems. We also provide gradient trajectory visualizations highlighting AlphaGrad’s ability to
maintain training stability and avoid local minima. These findings underscore AlphaGrad’s promise as a general-purpose solution for adaptive multi-loss optimization
in biomedical time-series learning.